How We Built LLM Infrastructure That Stays Up When Providers Don’t
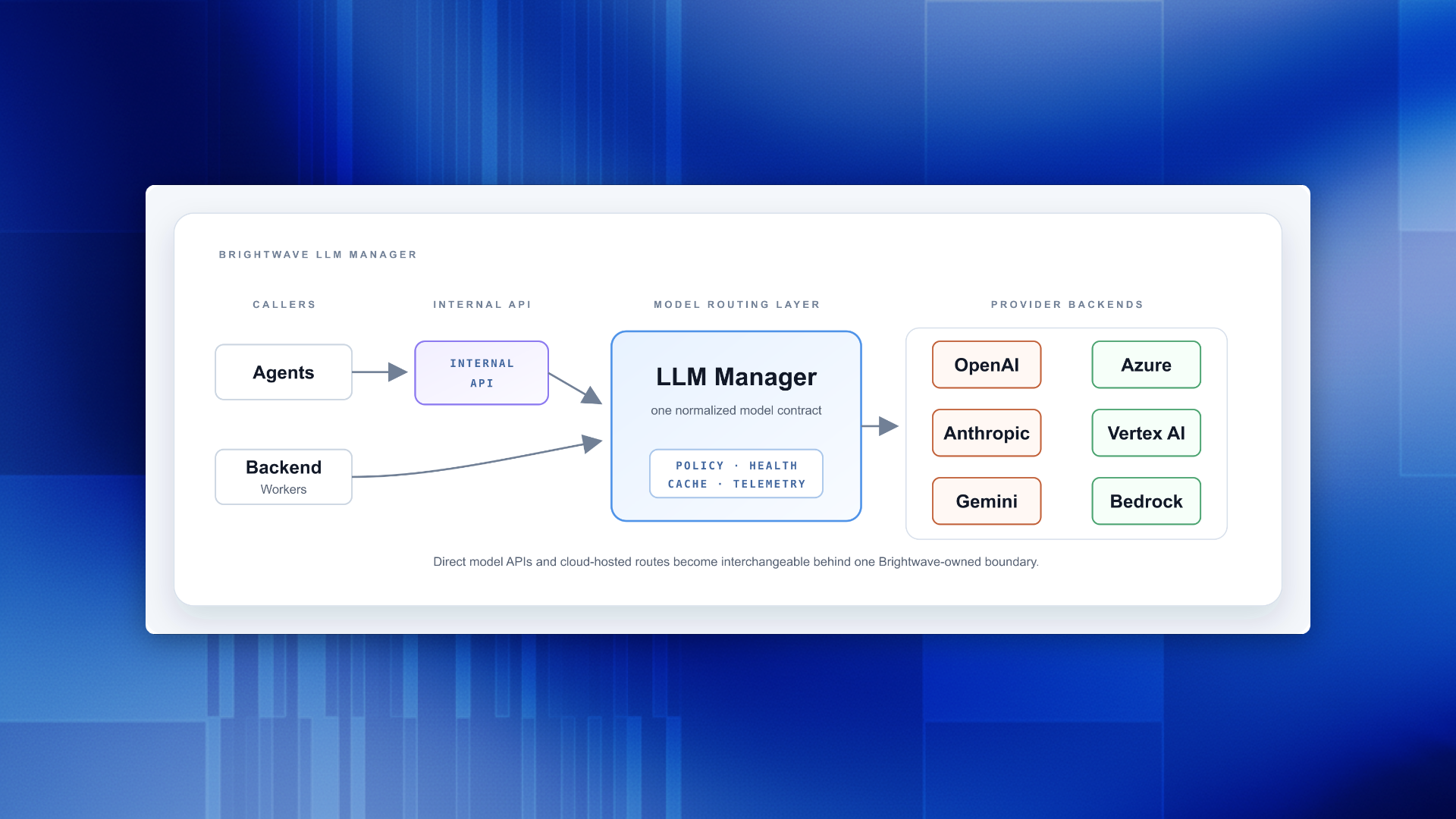
Brightwave’s LLM Manager turns model access into a governed, observable, failover-aware platform layer.
Every production AI company eventually discovers that its most fragile dependency is not a single model. It is the boundary between the product and the model providers.
In a prototype, calling OpenAI, Anthropic, or Gemini directly is fine. In production, that same decision becomes the place where provider outages, latency spikes, silent model regressions, token-cost surprises, cache misses, and vendor lock-in all converge. If every agent owns its own SDK calls, every provider incident becomes a product incident, and every model migration becomes a cross-codebase refactor.
At Brightwave, our agents synthesize research across thousands of documents and process billions of tokens a day. Users care about reliable answers, traceable work, and predictable latency. Internally, that volume also makes provider choice, caching, and model spend core infrastructure concerns. We needed one place to control model behavior without every agent learning every vendor API.
So we built the LLM Manager: a normalization, routing, failover, caching, and accounting layer between every agent and every model provider. Agents do not call model SDKs directly. They send one internal request to the manager. The manager picks the best healthy provider path, translates the request, streams the response back, and records usage and outcome telemetry in the same place.
We designed this boundary early in the platform’s development. Since then, providers have changed APIs, introduced new reasoning modes, added caching semantics, deprecated models, and shifted availability across direct and cloud-hosted backends. The implementations behind the manager have changed repeatedly. The contract above it has stayed stable.
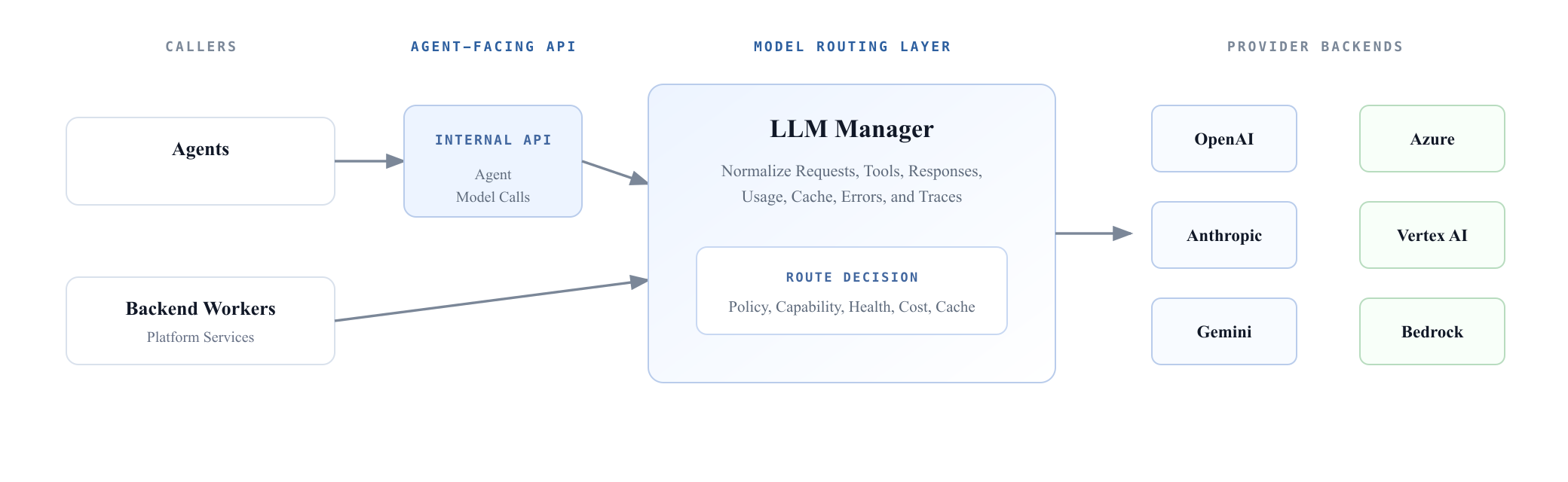
One Contract at the Model Boundary
The major model providers agree on roughly the shape of the problem and almost none of the details. Message formats differ. Tool-call schemas differ. Streaming events differ. Prompt caching differs. Reasoning tokens, usage accounting, safety metadata, and finish reasons all show up in different places.
Letting that leak into agent code is expensive. It means every agent has to know which SDK to import, how to build each provider payload, how to parse each provider stream, and how to recover when one path fails.
The LLM Manager keeps provider complexity at the boundary. Agents send one internal request shape: messages, tools, model preferences, cache hints, reasoning settings, and tracing metadata. The manager returns one normalized response shape: content, tool calls, errors, usage, cache accounting, and provider outcome metadata.
Provider adapters handle the vendor-specific work. OpenAI, Anthropic, Gemini, Azure, Vertex, and Bedrock can each have different payloads, streaming formats, cache semantics, and usage fields, but the rest of the system does not need to care.
The discipline is keeping the contract small. Most new provider features map onto concepts the interface already represents. When a capability genuinely needs new surface area, we add it once and every adapter that can support it gets it through the same path.
Why We Built It Internally
There are strong open-source model gateways, and LiteLLM is a good example of the category. But for Brightwave, the model boundary is too close to reliability, credentials, vendor strategy, and product behavior to outsource as a black-box dependency.
This layer sees prompts, tool schemas, provider credentials, routing policy, usage telemetry, and failure modes. It decides where every model request goes. That makes it a trust boundary, not just a convenience wrapper.
The 2026 LiteLLM PyPI incident is a useful reminder of why that matters. Malicious LiteLLM releases briefly entered the Python package supply chain after a credential compromise; PyPI later reported that the affected versions were downloaded more than 119,000 times during the attack window. The point is not that LiteLLM is uniquely risky. The point is that a generic gateway dependency can become part of thousands of AI systems' trusted path overnight.
Owning this layer lets us keep credentials and routing policy inside our own deployment boundary, audit dependencies deliberately, and design the system around our workload: long-running agents, prompt caching, health-aware routing, eval-curated model tiers, and fine-grained telemetry. We still learn from the ecosystem, but the system that decides where every model request goes is ours.
Defaults, Overrides, and Model Choice
Model selection cannot be scattered across dozens of agents and workflows. Operators need one place to move background research to a cheaper model, raise reasoning effort for analysis workflows, test a new high-tier model, or drain traffic away from a degraded provider.
Every task category — agentic chat, background research, planning, extraction, analysis — has a default model tier and reasoning effort. Each tier resolves to a curated set of models selected through internal evaluations and benchmarks, so routing reflects measured quality, latency, and reliability rather than vendor preference alone.
The default handles the normal case. Users can set a conversation to a specific model and reasoning effort when they want more control, and the system can also assign delegated work to a faster or stronger model when the subtask calls for it.
The important part is that these choices do not bypass failover. If a user sets a conversation to Anthropic Sonnet, the manager still decides whether to reach Sonnet through Anthropic directly, Bedrock, Vertex, or another available service provider based on health and configuration. The user picked the model experience they wanted; the manager preserves the safety net underneath.
Failover Uses Live Health
The simplest failover strategy is also the least useful one: call Anthropic, wait for the request to fail, then try another provider. That adds the latency of a failed request to the user experience and gives the system no principled way to recover when the provider becomes healthy again.
We wanted failover to happen before users felt the incident.
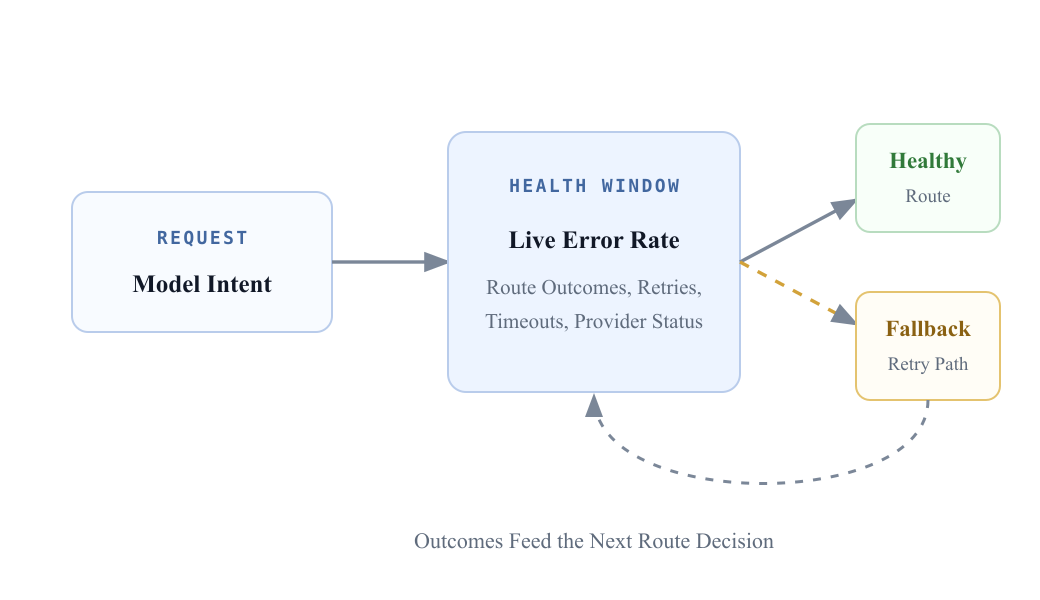
The LLM Manager tracks outcomes per model, provider, service provider, and endpoint in a five-minute sliding window. In plain terms, it is constantly asking: for this model, which paths are succeeding right now, which paths are timing out, and which paths are returning provider errors?
Recent outcomes count more than old ones. If Anthropic’s direct API starts timing out for Sonnet, that path’s health score drops and the manager stops sending traffic there. Requests for Sonnet can still go through Bedrock or Vertex if those paths are healthy. Successful calls feed back into the same health window, so recovery is automatic when the provider stabilizes.
Conversational workloads add one wrinkle: affinity. A multi-turn agent often benefits from staying on the same service provider because prompt-cache hits can materially reduce cost and latency. The router biases toward the same provider across turns, but only while that provider is healthy. Reliability wins over stickiness.
The result is that single-provider incidents are usually absorbed inside the platform. We have seen external provider status pages turn red while our customer-facing dashboards stay flat because traffic moved before the outage became visible at the product layer.
Caching, Spend, and Observability
Research agents are expensive to operate if they resend the same context on every turn. A system prompt, tool schema, workspace manifest, and document context can exceed 30,000 tokens before the task-specific work even begins. Managing cost well lets us give users access to state-of-the-art models without token limits or usage-based throttling. Without caching, that cost compounds quickly and unpredictably.
Providers expose prompt caching in different ways: explicit cache breakpoints, automatic prefix matching, cached-content APIs, and provider-specific constraints around where cache anchors can appear. Caching is explicit in the internal request: stable conversation context is identified before the provider call, and the manager translates that into the prompt-caching mechanism each backend supports.
The same call path records normalized usage for every response: input tokens, output tokens, cache-read tokens, cache-creation tokens, reasoning tokens, model, provider, service provider, agent type, task category, feature, latency, and outcome. Those dimensions power model-spend attribution, cache-hit analysis, SLO monitoring, provider health, and alerting.
This matters because the operational questions are connected. A model spend spike might be a prompt size regression, a cache miss, a tier change, a provider route change, or a reasoning budget change. A latency regression might be a degraded provider path, a longer reasoning trace, or a workload that lost cache affinity. Because routing, caching, and accounting all emit from the same boundary, we can answer those questions from one source of truth.
Adapters Contain Vendor Volatility
Each provider adapter handles client setup, option translation, message conversion, streaming assembly, tool-call parsing, error classification, usage extraction, and cache behavior for its backend.
That is where provider-specific behavior belongs. Anthropic streams tool inputs differently than OpenAI. Gemini reports reasoning usage differently than other providers. Bedrock and Vertex can expose the same upstream model through different contracts, quotas, regions, latencies, and failure modes.
The manager treats those as separate service providers under one logical model capability. That lets us add adapters, retire deprecated models, rebalance traffic between direct and cloud-hosted routes, and test new providers without changing what agents ask for.
What We Learned
Own the model boundary. Raw SDK calls are easy to start with and expensive to unwind. A small internal contract between agents and models gave us the freedom to change providers, routes, caching behavior, and telemetry without rewriting product logic.
Separate model choice from provider route. A user can choose a model and reasoning effort for a conversation while the infrastructure decides where that request should run. That separation is what makes vendor independence real.
Failover has to be proactive. Retrying somewhere else after a request fails is not enough for user-facing AI workflows. Live health scoring, automatic recovery, and cache-aware affinity are what turn failover into reliability.
Internal cost control and reliability need the same data. The model, prompt, cache behavior, reasoning effort, latency, route, and outcome all describe the same event. Tracking them together makes model spend and gross-margin exposure explainable instead of anecdotal.
A stable contract is an infrastructure asset. The provider ecosystem will keep changing. New models, new APIs, new pricing, new limits, new hosted routes, new failure modes. The more stable the internal boundary, the more aggressively the company can take advantage of those changes without exposing users or agents to churn.
The payoff is practical. Agents get one durable interface. Operators can change model policy centrally. Users get a product that keeps working through provider incidents. Engineering can adopt new models and routes without destabilizing the application. Finance gets token-level visibility into model spend.
We did not make model providers interchangeable by pretending they are the same. We made their differences measurable, routable, and contained behind one boundary that Brightwave owns.