Giving a Cloud Agent Hands on Your Machine
A sandbox is a comforting thing. Our research agents run inside disposable Linux containers with no real credentials and a proxy that decides what traffic leaves. If one of them gets hijacked by a poisoned document, the damage is bounded by walls we built and can tear down. We've written about that architecture before.
Now point the same agent at a user's actual laptop. Let it read the project folder on their desktop, drop a finished deliverable back next to the source files, run a command to unzip an export, drive a desktop app to pull a value out of a legacy tool. Every one of those is a real customer ask. And every one of them moves the blast radius from a container we can throw away to a machine we can't — one with the user's documents, their SSH keys, their whole working life on it.
You can't sandbox that away. The files are the point; the agent is supposed to touch them. So the question stops being "how do we contain the agent" and becomes "how do we let a cloud agent act on someone's real machine without it ever being a liability." This is the system we built to answer that, and the design decisions are most of the interesting part.
The threat model is not "evil agent"
Start with what you're actually defending against, because it's easy to get this wrong.
The naive framing is "what if the agent goes rogue." The real framing is that the model is the untrusted component by construction. It reads documents, web pages, and emails that an attacker may have authored. Prompt injection means any of that content can become instructions. So the agent that asks to delete a file might be doing exactly what the user wants, or it might be doing exactly what a hidden line of white text in a PDF told it to do — and from inside the system, those two requests are byte-for-byte identical.
That kills an entire category of solutions. You cannot ask the model to be careful. You cannot harden a system prompt into a security boundary. You cannot let the agent's own judgment decide whether an action is safe, because the agent's judgment is precisely the thing that's been compromised. Every control that matters has to live below the model, enforced by code that doesn't care what the model believes it's doing.
Our prior post landed on a one-line principle for the cloud sandbox: security properties should be enforced by infrastructure, not by the model's judgment. The host is the same principle on harder ground — there's no disposable container to fall back on, and the consequences are personal.
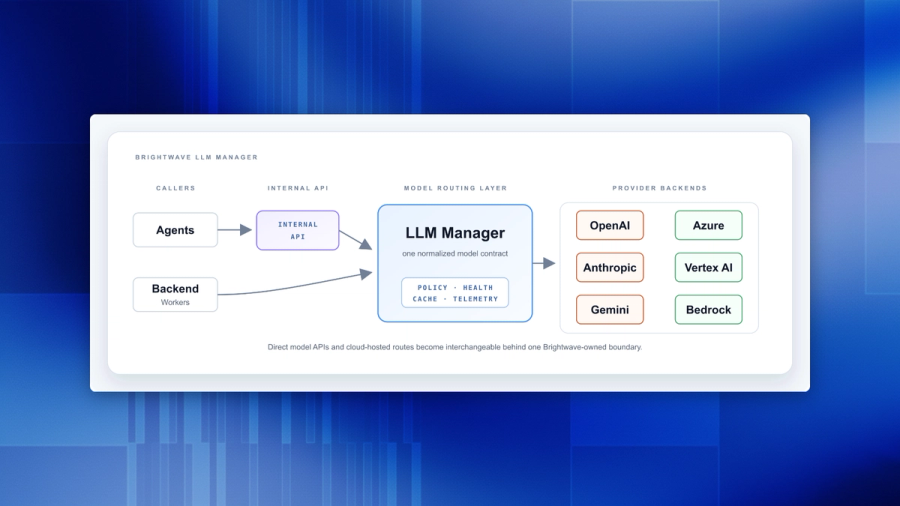
A broker, not an agent
The first decision was structural, and it's in the name.
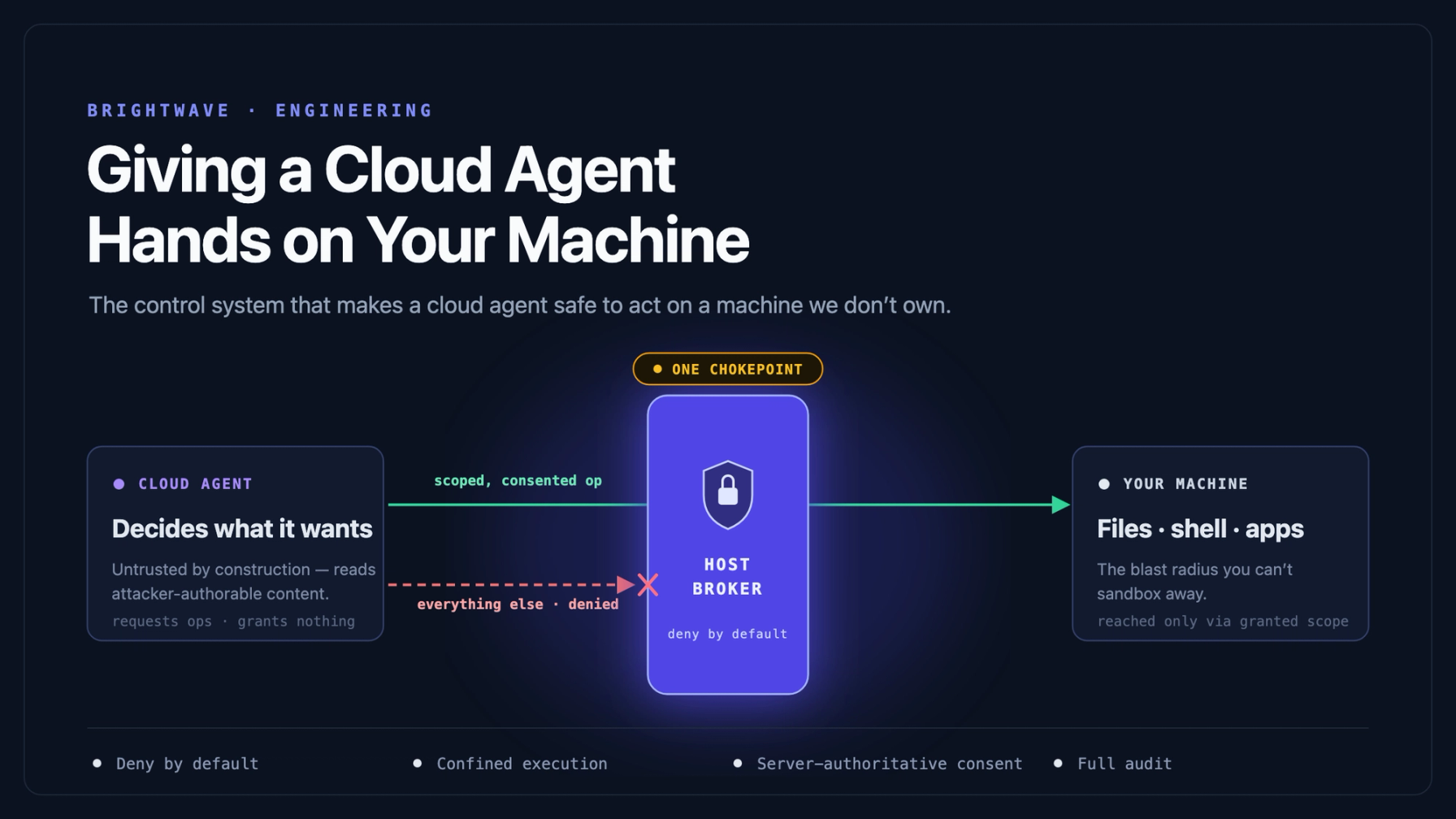
The component that touches the machine is a dedicated process we call the host broker. It is deliberately not an agent. An agent reasons and acts on its own; a broker mediates someone else's request onto a resource under explicit rules, and does nothing on its own initiative. That distinction isn't branding — it's the entire security posture compressed into one word. The broker has no autonomy to take away because it never had any. It receives typed requests, checks them against granted permissions, and either performs a narrow operation or refuses.
The cloud agent decides what it wants. The broker decides what is allowed. Those two jobs never live in the same process.
Three properties fall out of making it a separate process rather than logic stapled into the desktop app:
- One chokepoint. Every operation that touches the machine flows through one place. There is no second code path, no "quick helper" that writes a file directly. If it touched the disk, it went through the broker, which means it went through a permission check and an audit record. A single chokepoint is the only kind you can actually reason about.
- Crash isolation. The broker is separate from the UI process, so a fault in host-interaction logic can't take down the app, and a fault in the app can't leave a half-finished filesystem operation in an undefined state.
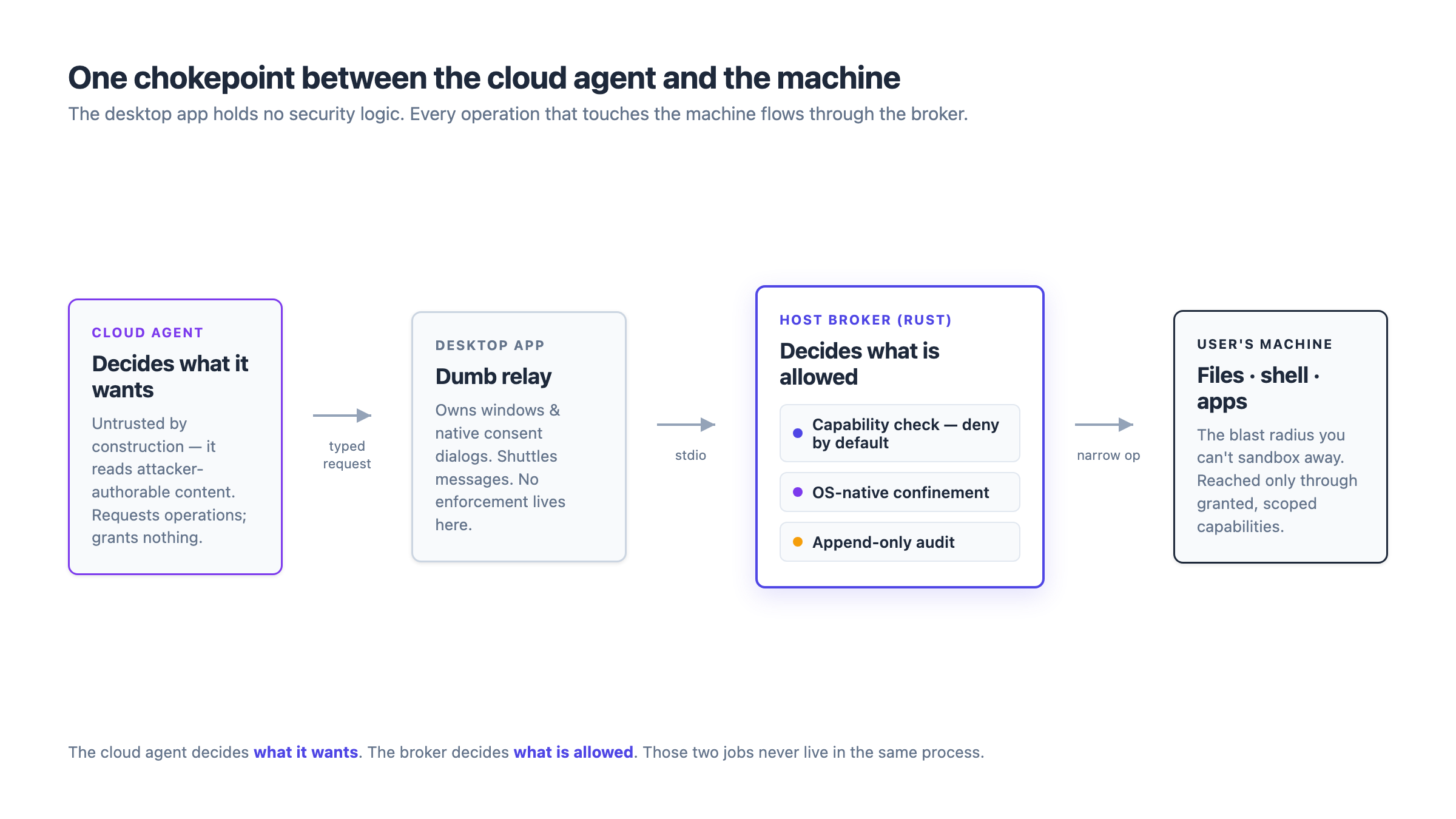
- The desktop app is a dumb relay. This one matters more than it sounds. The app shell — the Electron layer that owns windows and native dialogs — holds no security logic at all. It shuttles messages to the broker and renders native consent prompts. All enforcement lives in one auditable surface. When the desktop frontend is rewritten or a second host adapter shows up, the security boundary doesn't move, because it was never in the frontend.
We wrote the broker in Rust, as a runtime-agnostic core. The host shell is incidental; the policy engine is the asset.
Deny by default, capabilities instead of ambient authority
The broker grants nothing implicitly. There is no "the agent has access to the machine." There are only narrow, typed capabilities — read files, import files, write files, run a shell command, drive an app — each one scoped to a specific resource: a particular folder, a subtree under it, a single application, never "everything."
Every operation the broker can perform declares exactly which capability and which scope it requires, and an authorization check runs before the operation, every time, defaulting to refusal. An agent request to write a file is checked against "may this project write to this folder" and denied unless a matching, in-scope grant exists. This is the difference between ambient authority — the process can do whatever its OS user can do — and capability-based authority, where holding a reference to an operation is the only way to invoke it, and references are handed out deliberately and narrowly. Ambient authority is how a single compromised step turns into full machine access. Capabilities are how you stop that by construction.
Crucially, the boundary itself — which folders, which access types — is only ever set by an explicit human action. No grant is ever inferred from something the model said. The agent can request access; only a person, clicking a native OS dialog, can grant it.
Consent tiered by blast radius
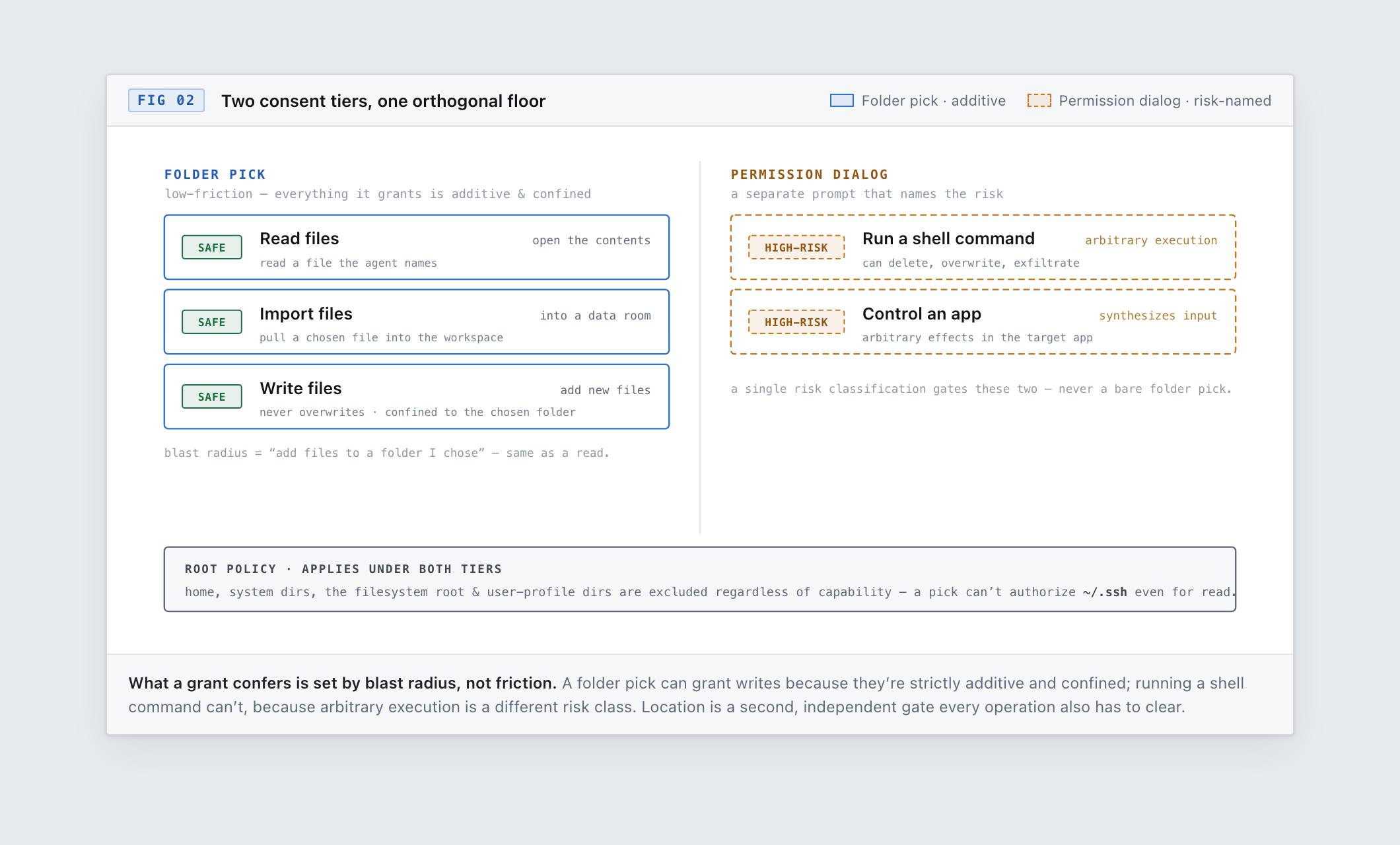
Not every capability is equally dangerous, and pretending they are just trains users to click through prompts. So consent is tiered by what the operation can actually do.
Picking a folder in the OS file dialog is itself a meaningful act of consent — you've chosen exactly this folder — so it can confer the additive, low-blast-radius capabilities: reading, importing, and a deliberately constrained kind of writing. The write is constrained to the point of being boring on purpose: it refuses to overwrite anything that already exists, refuses to follow symlinks out of the chosen folder, and is confined to the folder you picked. Its worst case is "a new file appeared in a folder I chose," not "my data got destroyed."
Running an arbitrary shell command is a different risk class entirely — it can delete, overwrite, and exfiltrate in one line — so it never rides on a folder pick. It requires its own explicit, risk-naming consent. The point is to spend the user's attention where the blast radius actually is, and not to dilute a real warning by surrounding it with five fake ones.
This is orthogonal to location: sensitive roots like the home directory, system directories, and credential stores are excluded from grants regardless of capability, so no amount of clicking can authorize the agent to read ~/.ssh.
The structural defense: the agent can't grant itself anything
Here is the design decision I'd defend hardest, because it's the one that holds when everything else is compromised.
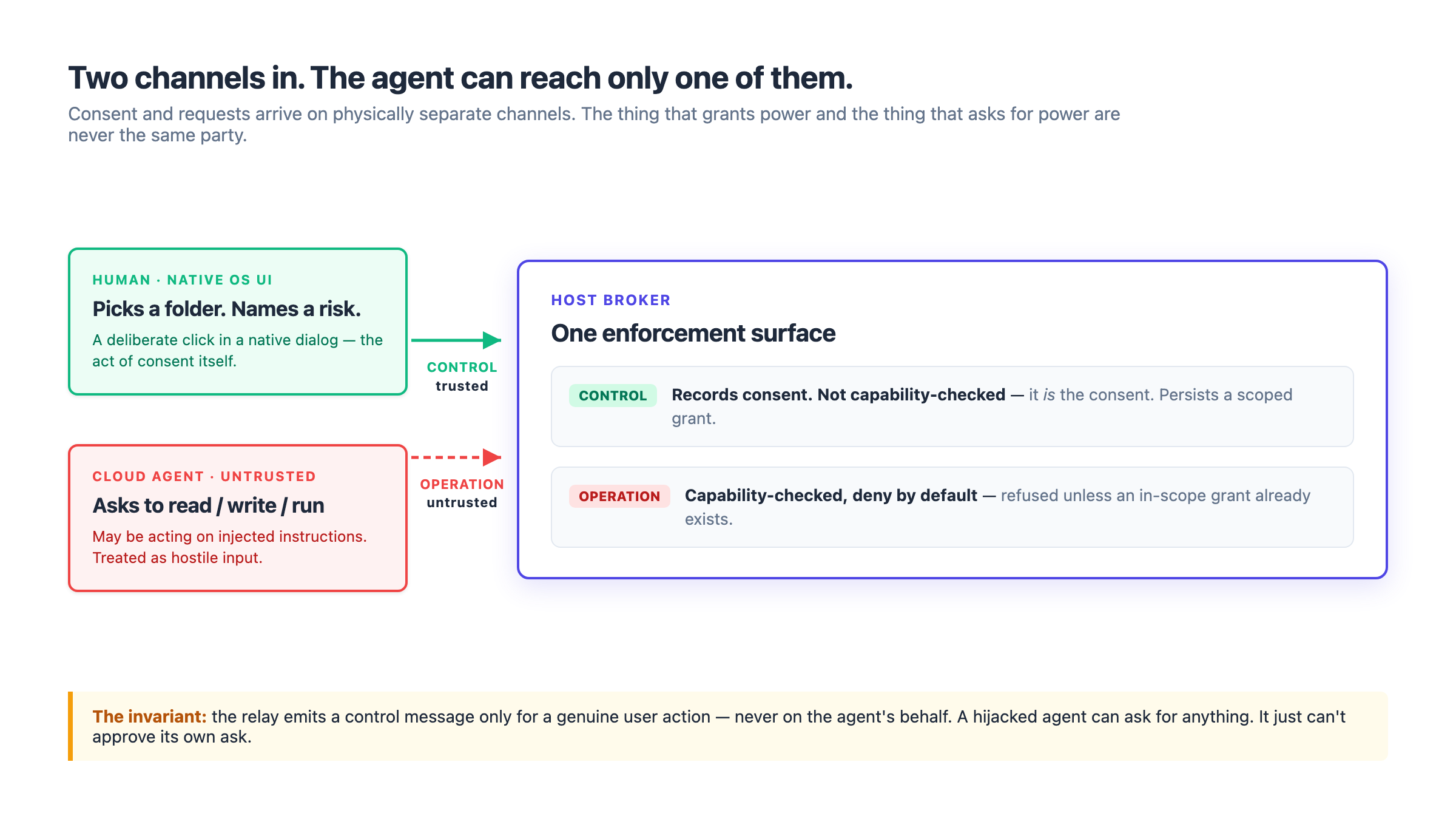
Requests into the broker arrive on two separate channels. One channel carries agent-originated operations — read this, write that, run this command. Every message on it is untrusted and capability-checked. The other channel carries control messages — "the user just picked this folder, register it as a grant." Control messages are trusted and not capability-checked, because they don't represent the agent asking for anything; they represent a consent decision a human already made in native UI.
The security of the whole system reduces to one invariant: the relay may only ever emit a control message in response to a genuine user action, and never on behalf of the agent. A folder grant exists because a person clicked a folder picker, full stop. The agent has no path to the trusted channel. It cannot phrase an operation cleverly enough to become a consent. The thing that grants power and the thing that requests power are physically different channels, and only one of them is reachable by the untrusted party.
This is what makes "the model is compromised" survivable rather than catastrophic. A hijacked agent can ask for anything it likes. It just can't approve its own ask.
Even with a grant, the model's judgment is still not the boundary
A grant says the agent is allowed to run a command in a folder. It says nothing about what that command does. So execution gets a second, independent layer: OS-native confinement.
When the broker runs a shell command, it doesn't run it in the broker's own process. It launches a separate, confined child using the platform's real sandboxing primitives — sandbox-exec profiles on macOS, Landlock plus seccomp on Linux, AppContainer plus a Job Object on Windows. Inside that jail, network egress is blocked on every platform (the exfiltration threat from prompt injection doesn't get a network), writes are confined to the granted scope, and a runaway process gets killed on a timeout.
And the load-bearing rule: if confinement can't be established, the operation is refused — it never degrades to running unconfined. Fail closed, always. A confinement primitive that "falls back to just running it" when the sandbox is unavailable is not a security boundary; it's a security boundary with an off switch the attacker can reach. We'd rather the shell simply not be available on a platform than be available without its jail. Read and import still work; arbitrary execution waits for a real sandbox.
This mirrors the cloud-sandbox principle exactly. The grant is consent; the sandbox is enforcement. A compromised agent with a valid grant hits the same walls as a well-behaved one.
Consent that survives the real world
Per-action human approval is easy to draw and hard to build, because the hard part isn't the prompt — it's everything that happens around it.
First, the gate is server-authoritative, not client-advisory. A client-side gate can, in principle, be skipped by a buggy or tampered renderer, so the decision about whether a high-risk action may proceed is enforced on the server: the action literally cannot be dispatched to the machine until the server has recorded a matching approval. A compromised client can't click "yes" on the user's behalf, because the client isn't the thing that decides.
Second, approval has to be durable. Real users walk away. They close the laptop, the backend redeploys, they come back in three hours. A consent gate built on a held connection or an in-memory wait would silently turn "the user stepped out" into "auto-approved" or "auto-failed." So a pending approval is durable state, not a blocked coroutine — it survives restarts and long idle by construction, and a stale request expires on a timescale measured in hours, not the minutes you'd use for a transient hiccup.
Third, prompting on every action doesn't scale, so consent is a dial, not a constant. A per-conversation permission mode governs how aggressively safe actions auto-approve within the already-granted boundary — from "ask me about anything that mutates" through "let an evaluator triage the obviously-safe ones" to "act freely in the folders I've granted." The dial moves autonomy. It never moves the boundary, and it never touches confinement: in every mode, the shell stays jailed and network-blocked. "Full access" removes prompts, not walls. These are two orthogonal axes — how much can the agent reach and how much do I want to be asked — and keeping them orthogonal is what keeps the model coherent as it grows.
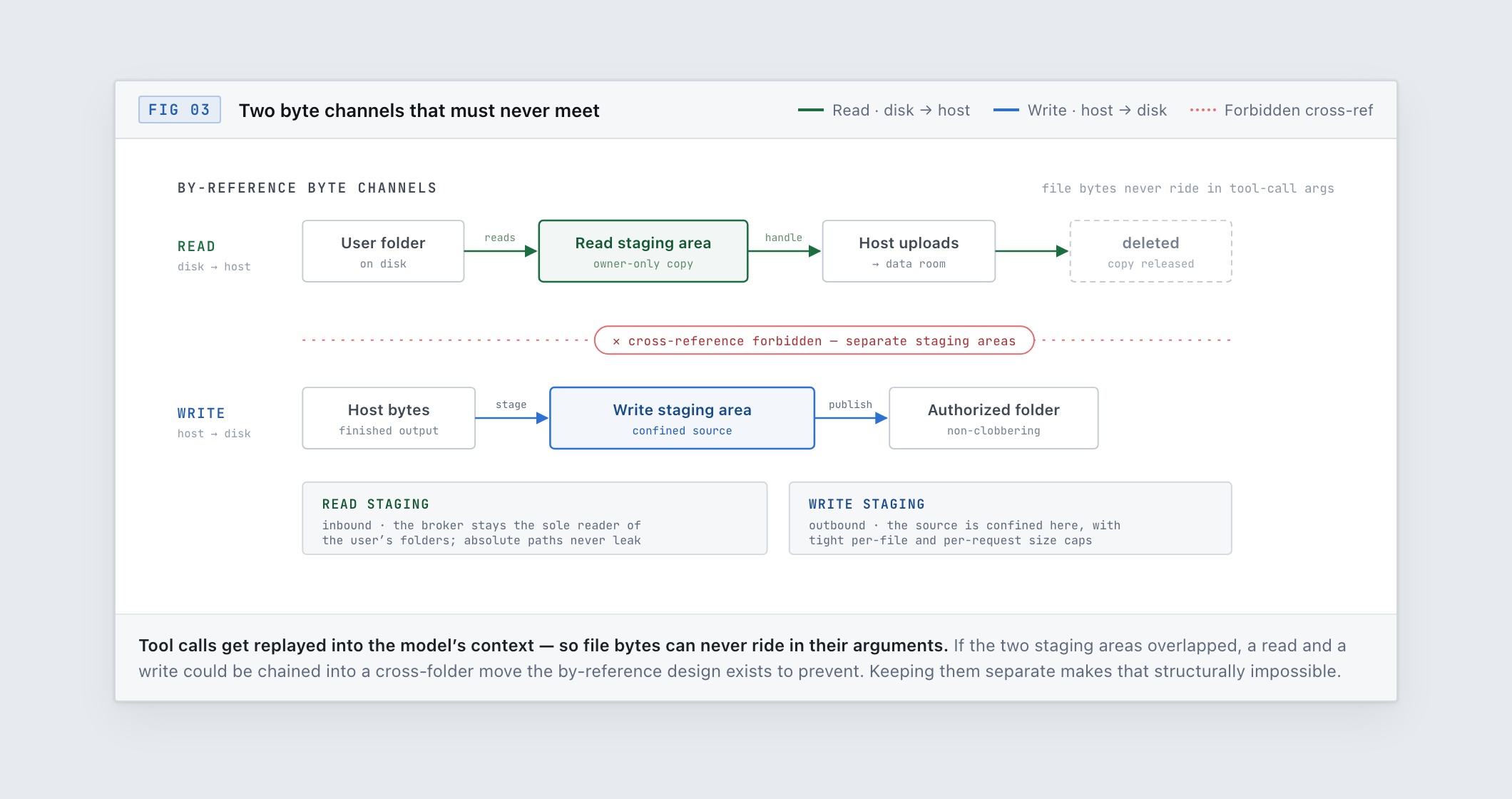
One detail with outsized payoff: file contents never travel through the model's context. When the agent writes a file, it references content by a workspace handle, not by inlining bytes into a tool call. When it imports a file, the bytes are staged into the broker's own scratch space and handed off by an opaque reference. The model orchestrates the movement of data without the data passing through the prompt. That keeps secrets out of the model context, keeps large files from blowing up token budgets, and keeps the record of what the agent did replayable without replaying gigabytes through an LLM.
Audit, because a boundary you can't inspect isn't one
Every operation that touches the machine is recorded: what happened, when, against which grant, and with what outcome. When several grants could have permitted an action, the record names the specific one that did — you can't audit "some permission allowed this."
Two choices give the trail teeth. The record is de-sensitized — folder-relative paths, never absolute paths, never file contents — because an audit log of which private files a user touched on their own machine is itself sensitive, and forwarding it anywhere is a privacy decision, not a default. And mutating operations record their intent before they act and refuse if that record can't be made durable. The failure mode we engineered for is "an over-record" — an intent with no matching outcome, because a crash interrupted it — never "an unaudited mutation." A machine-touching operation that left no trace is the one thing the system structurally won't do.
What we'd tell another team
The hard part wasn't the permission engine. Capability checks and path containment are tractable, well-trodden problems. The hard part was the consent plumbing being durable and server-authoritative under every failure mode — the user who walks away for three hours, the backend that redeploys mid-decision, the second browser tab, the client you can't trust to enforce its own gate. That's where the real engineering went, and it's the part that doesn't show up in a demo.
And the orthogonality lesson generalizes past this feature: which resources the agent can reach and how much autonomy it has within reach are different axes. Conflating them produces a permission model that's either too coarse to be safe or too fiddly to use. Kept separate, each one stays simple.
The payoff is that a user can point the agent at the real folder where their actual work lives, let it read the source files and drop a finished deliverable back beside them, and trust that the worst a hijacked model can do is hit a wall and ask for help. The cloud sandbox made the power safe to grant inside a container we own. The host broker makes it safe to grant on a machine we don't.